

Low Bitrate Speech Codec powered by ML
How I made, or in actuality enhanced, a low bitrate speech codec with the power of neural networks


Motivation
Neural networks have always been something I was interested in, but I never actually got to use them in a personal project. The thought always lingered inside my mind, so as soon as I got the idea of using one to create (or as I later found out - improve) a speech codec - I jumped on it.
All of my previous work surrounding NNs was mostly using pre-trained ones, so this would be my first fully-fledged NN project. This is why I invested quite a lot of time and effort into research.
Why low bitrate?
You might ask yourself what low bitrate even means in this context and why it would be beneficial.
In terms of actual numbers, my codec only uses 800 bit/s (bits per second) compared to something like Opus which uses 6 kbit/s (kilobits per second) at the minimum. Of course, the quality is way better - but my point was just to show how little this is. Some other codecs can be seen in the illustration below.

Low bitrate means that the data (or what is sent over the medium) is of low volume over time. This means that we transfer a useful amount of information without taking up too much of the transfer medium.
This provides numerous benefits, some of them being the ability to have a voice conversation with really bad signal quality or providing multiple voice conversations without having much bandwidth.
Research
Already a solved problem?
First off, I wanted to know if something like this had been done before, and it has - albeit without much public information. I did however see a few real-life usable projects like Google Lyra and others. At a later point, I also found Meta's AI EnCodec however I already had my working model.
Initial experiments
Following that investigation, I looked at what was possible from a pure synthesis standpoint (aka spectrogram to voice, or even full TTS). This phase took more time than you’d expect since it was my first time using PyTorch and seeing models of this kind (generator + discriminator). I tested most of them with some sample data, checking both the inference times and whether the output was adequate.
The first dead end
Being enticed by the amazing quality achieved by those GAN models, the initial idea was to just set up a pipeline of something like:
Algorithmically extract some features from the input audio
Pass it into a trained NN capable of encoding that data into some IR (intermediate representation), and back
Transfer that IR over some medium
Convert the IR back into the initial features (approximately, of course)
Use a pre-trained GAN to synthesise an approximation of the initial audio
For many reasons, this did not work... Mainly the fact that I just didn't have enough time and knowledge to implement it at that point. Most of the ideas and motivation came from Agustsson et. al. in Generative Adversarial Networks for Extreme Learned Image Compression and the respective implementation by JTan.
A simpler solution
So by this point, a few weeks had passed and I found myself thinking about what even "features" were. And then SUDDENLY, it came to me - I don't need to reinvent the wheel, I might as well just use a pre-existing low-bitrate codec and export some of its parameters, normalize them and use them as some sort of features while training a pre-designed model.
Setup
Decisions
At this point, I had to pick a codec and a network to train.
For the codec decision, I didn't have many options - but I won't disclose the one I picked (not OSS). It doesn't matter since any codec might work, but what I want to present to you are the thought and design processes behind the project.
For the network, I tested a wide variety of options but ultimately decided on HiFiGAN provided by the excellent ParallelWaveGAN project. The choice was mainly motivated by the clean organization of the code, ease of switching between the models (something which was important during my experiments) and the license.
Another concern was being able to run the network on real hardware, like an iPhone or an embedded board with NPU hardware. For this, It was almost a necessity to have a network which didn't require data manipulation or transformation before or after inference. I didn't want to bother finding math and other transformative libraries in C++/Rust and ONNX model conversion now just "w o r k s".
# y_ (generator output audio) is a 1D array of audio samples
# x (input features) is a multi-dimensional tensor of features
# therefore no other magic is required :)
y_ = self.model["generator"](*x)
Training workflow
So the way all GAN networks work is by having a discriminator learn to distinguish the generator's fake data from real data. The generator is fed by some features and penalized by the discriminator for producing implausible results.
In my case, it works like this:
Fake data: audio output we later end up using (since only the generator part is important for inference)
Real data: training audio data
Generator features: the same training audio data encoded and then decoded by the codec into the features
In summary, I replaced ParallelWaveGAN's algorithmic feature extraction (Mel-spectrum) with my codec's encode + decode (feature dump only, no audio synthesis).
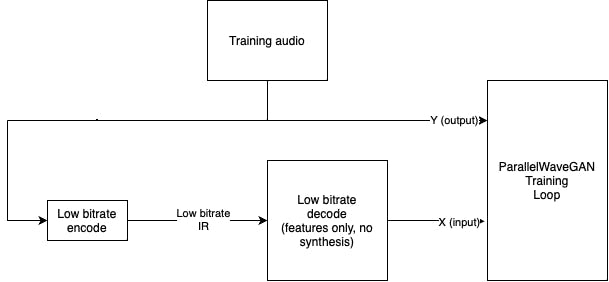
Extracting the features
This mainly consisted of going through the decoder and finding points at which we have some usable values, evaluating their quality by trying to train a network on them. Rinse and repeat. Of course, all of this could be done better by someone more knowledgeable on the topic of voice codecs, but at this point, the project was mainly an experiment.
In the illustration below, you can see how I tried extracting features at different points of the decoder architecture, and I ended up with a combination of them which provided the best results.
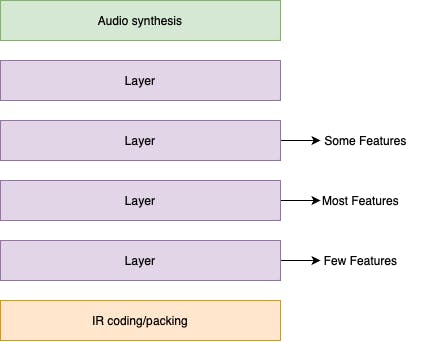
I also did some basic normalization since dataset-wide normalization didn't provide much benefit and the features were almost always inside a certain range so I just scaled it to between 0 and 1.
Dataset
For data, I used the OpenSLR LibriTTS dataset.
LibriTTS is a multi-speaker English corpus of approximately 585 hours of read English speech at 24kHz sampling rate, prepared by Heiga Zen with the assistance of Google Speech and Google Brain team members.
Since my codec was 8kHz, I also had to downsample it - I'm not entirely sure how this impacted performance.
Finally, I made a simple Python script which took the downsampled audio and its decode features and turned the pair into a NumPy binary*.*
Training
Most of my experiments were done on Google's Colab, but as soon as I tried anything remotely more complex than the smallest dataset - I realised it wasn't going to cut it.
After a few days of trying to get Google to lend me a GPU via their cloud with no success, I found Lambda.
With their service, I was up and running in no time. I migrated my Colab notebooks without much trouble and went on the first bigger training run.
The first few runs weren't that great, and after a bit of fiddling with ParallelWaveGAN settings, I decided on the config with which I would commit to a full run.
The run ended up taking something like 3 days with the whole dataset, and resulted in a pretty poor loss figure - but I liked the output. Of course, it could always be better, but my POC was here!
Results
Here are the results. (link to my Google Drive)_orig files are the originals, and the ones without the extension are my regenerated ones.
Since the codec I used is at 800 bits per second, it generates 256 bits of data every 320 milliseconds from 2560 audio samples (the audio is 8KHz).
I trained the network only on English voices, and therefore everything other than English sounds pretty bad - I won't even post those results.
As you can see, some of them are pretty good, but some are downright awful (especially 27w, but to be honest the original isn't good either). It is probably caused by a lack of training on voices with similar voice features.
Final words
What I've learned
I am proud of what I've achieved with this project. It surely has been a great learning experience, especially since this isn't some basic hello world thing which has been done a thousand times - but something I took from an idea to an actual product doing it with a technology I didn't know much about.
Improvements
The biggest improvement (and I can't stress this enough) will be to ditch the human-made codec.
To achieve the best possible performance, the machine should learn patterns in a spoken human voice - and design an applicable IR from that. It could even be tuned specifically for a single language, or a subset of a single language - to achieve an extremely low bitrate.
Another idea is to possibly send a voice model for a specific person upfront (not low bitrate), and then only send an extremely lightweight IR especially fit for that model.
Next steps
I'm still working on this project, albeit not at the network level.
Things I am currently interested in are finding platforms (or even custom hardware) on which such a model can be run, and will post about my progress in the following posts. I got it running on my iPhone, but I still don't have enough to write a high-quality article.
Another thing I'm interested in is creating a POC, in which the low bitrate benefits of this codec are shown.
Any follow-up posts will be linked below! :)